核心思想。三步走。(1) 用生成流网络(GFlowNet)取代 RL,它按 $P_\theta(\alpha)\propto R(\alpha)$ 对 $\alpha$ 进行采样——多样性来自采样器本身,而非附加的惩罚项。 (2) 用在公式抽象语法树(abstract syntax tree, AST)上运行的关系图卷积网络(RGCN)取代序列式(LSTM)编码器,使具有数学结构的公式获得结构化的嵌入表示。 (3) 采用稠密的多面奖励(multi-faceted reward)(IC + 结构感知 + 新颖性)来解决奖励稀疏(reward sparsity)问题。
为什么用 GFlowNet 而非 RL?
在 AlphaGen(第 2 讲)中,PPO 策略收敛到使期望奖励最大化的单一公式。这正是 RL 的设计目标:找到奖励地形中的众数(mode)。但对于 alpha 挖掘而言,众数是错误的目标。一个组合需要的是许多弱相关的信号,而非一个强信号。AlphaGen 试图通过奖励池的组合 IC 来解决这一问题,但策略仍会坍塌:一旦池被填满,梯度就会把每个新公式推向能带来最大边际改进的那种函数形式,于是生成器停止探索。AlphaForge 用一个多样性损失来打补丁,但它与适应度目标相互权衡——两个损失彼此对抗,而帕累托权重是一个棘手的调参难题。
GFlowNet 从结构上解决了这个问题。GFlowNet 学习的不是最大化奖励,而是按与给定奖励函数成正比的概率去采样对象(此处即公式):$P_\theta(\alpha) \propto R(\alpha)$。高奖励公式被采样得更频繁,但具有不同结构的中等奖励公式也会以与其质量相称的频率被抽到。这意味着多样性无需任何额外的损失项——它自动地从采样目标中产生。一次训练运行就能在公式空间上产出一个完整的分布,而从该分布反复抽样便能"免费"获得一池高质量、不冗余的 alpha。
关键直觉:RL 问的是"哪一条动作序列是唯一最优的?",而 GFlowNet 问的是"鉴于每条动作序列结果的好坏,它应当被赋予多大的概率?"前者收敛到一个点,后者收敛到一个分布。
轨迹平衡(trajectory balance):训练目标
GFlowNet 逐步构建一个对象(此处即公式):从状态 $s_0$(空)$\to s_1 \to \cdots \to s_n$(完整公式)。前向策略(forward policy) $P_F(s_t \mid s_{t-1};\theta)$ 决定在每一步追加哪个 token/算子。 后向策略(backward policy)$P_B(s_{t-1} \mid s_t;\theta)$ 定义了对公式的一种概念性的"逆向拆解"——它在推理时从不运行,但在训练时用于建立流匹配约束。$Z_\theta$ 是一个可学习的标量,估计穿过构造有向无环图(DAG)的总"流量"(类比于玻尔兹曼分布中的配分函数)。
轨迹平衡(trajectory balance, TB)损失强制一个核算恒等式:对于每条完整轨迹 $\tau = (s_0, s_1, \ldots, s_n)$,配分函数与所有前向转移概率的乘积,必须等于终端奖励与所有后向转移概率的乘积。
$$\mathcal{L}_{\text{TB}}(\tau)=\Bigl(\log Z_\theta+\sum_t\log P_F(s_t\mid s_{t-1};\theta)-\log R(s_n)-\sum_t\log P_B(s_{t-1}\mid s_t;\theta)\Bigr)^2,$$通俗地说:当构建一个公式的前向概率(经 $Z_\theta$ 缩放)恰好等于该公式的奖励乘以拆解它的后向概率时,损失为零。当这一平衡对所有轨迹都成立时,可证明边际采样分布 $P_\theta(\alpha)$ 与 $R(\alpha)$ 成正比。
最终训练目标加入一个熵奖励项,以鼓励训练早期的探索:
$$\mathcal{L}_{\text{final}} = \mathbb{E}_\tau\bigl[\mathcal{L}_{\text{TB}}(\tau)\bigr] + \beta \cdot \mathcal{L}_{\text{ENT}}$$也就是采样轨迹上的期望 TB 损失,加上一个以 $\beta$ 加权的熵正则项,它防止前向策略过早集中。
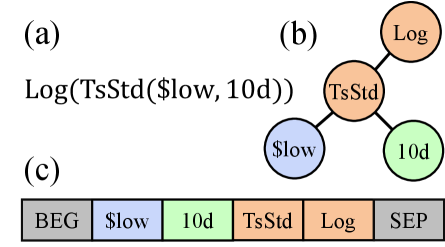
架构
抽象语法树上的 RGCN
AlphaGen 与 AlphaForge 都将公式表示为扁平的 token 序列,并用 LSTM 编码。这对语言有效,但公式不是句子——它是一棵树。表达式 ts_mean(close / open, 20) 有一个根算子 ts_mean、一个左子树 close / open,以及一个右叶子 20。LSTM 以某种线性化顺序(逆波兰记法)看到 token,但它并不内在地知道 close 和 open 是 / 的两个操作数,或者 / 是 ts_mean 的左孩子。树结构必须从位置线索中推断,而 LSTM 往往做不到这一点,尤其是对深度嵌套的公式。
AlphaSAGE 将每个公式解析为其抽象语法树(AST)——见上图面板 (b)——并直接在该树上应用关系图卷积网络(RGCN)。每个节点 $v$(算子或操作数)都有一个可学习的初始嵌入 $h_v^{(0)}$。RGCN 定义了三种关系类型 $\mathcal{R}$:左孩子、右孩子和算子–操作数。每种关系类型 $r$ 在每一层 $l$ 都拥有自己的权重矩阵 $W_r^{(l)}$,因此网络可以为"我是某个除法的左参数"与"我是某个除法的右参数"学习不同的聚合规则——这种区别正是扁平序列所抹去的。
在第 $l$ 层,每个节点 $v$ 通过聚合各关系下来自其邻居的消息(按关系特定的度 $c_{v,r}$ 归一化),再加上一个权重为 $W_0^{(l)}$ 的自环,来更新其隐藏状态:
$$h_v^{(l)}=\text{ReLU}\!\Bigl(\sum_{r\in\mathcal{R}}\sum_{u\in\mathcal{N}_r(v)}\tfrac{1}{c_{v,r}}W_r^{(l)}h_u^{(l-1)}+W_0^{(l)}h_v^{(l-1)}\Bigr),\qquad e_\alpha=\text{MaxPool}\bigl(\{h_v^{(L)}\}\bigr),$$通俗地说:每个节点查看其父节点和子节点,接收每个邻居状态的关系特定线性变换,在每种关系类型内取平均,跨关系类型求和,加上自身的上一状态(自环),再经过 ReLU。在 $L$ 层这样的消息传递(message passing)之后,对所有节点嵌入做最大池化,将可变大小的树压缩为单个固定维度的公式嵌入 $e_\alpha$。选用最大池化(而非平均池化)是为了让最"活跃"的节点特征占主导——以捕捉公式的标志性算子。
嵌入 $e_\alpha$ 正是 GFlowNet 前向策略据以进行下一动作预测的表示。由于结构相似的公式会产生相似的嵌入(共享的子树模式会产生共享的消息传递激活),策略便能在不同公式之间泛化——这是一种归纳偏置,消融研究证实它是 AlphaSAGE 相对基线性能提升的最大单一贡献者。
多面稠密奖励
公式搜索中一个关键的实践问题是奖励稀疏(reward sparsity)。大多数随机组装的公式在语法上有效,但在金融上毫无意义(IC 接近零)。如果奖励仅为 IC,绝大多数轨迹收到接近零的信号,GFlowNet 几乎无从学习。AlphaSAGE 用一个三分量的稠密奖励来应对,即便对平庸的公式也能提供梯度信号:
IC 奖励 $R_{\text{IC}}(\alpha)$:公式输出与前向收益之间、按时间平均的横截面秩相关的绝对值。这是标准的预测能力度量。
$$R_{\text{IC}}(\alpha) = \bigl|\mathbb{E}_d\bigl[\text{Corr}(\alpha(\mathbf{X}_d), \mathbf{y}_d)\bigr]\bigr|$$也就是把所有训练日期的每日横截面相关求平均,再取绝对值(符号无关紧要,因为你总可以翻转持仓方向)。
结构感知奖励 $R_{\text{SA}}(\alpha_i)$:惩罚那些行为(输出时间序列)与其结构邻居不相似的公式。结构邻居是指 RGCN 嵌入在余弦距离上最接近的 $K$ 个公式。其思路是:两个 AST 几乎相同的公式应产生相似的输出;如果一个公式在结构上接近优秀表现者,但行为却差异很大,那就有问题——它可能在对噪声过拟合。该奖励随到 $K$ 个最近结构邻居的加权行为距离呈指数衰减:
$$R_{\text{SA}}(\alpha_i) = \exp\Bigl(-\sum_{j \in \mathcal{N}_K(\alpha_i)} w_{ij} \cdot d_{\text{behav}}(\alpha_i, \alpha_j)\Bigr)$$通俗地说:如果一个公式的输出与结构相似公式的输出一致,结构感知奖励就高(接近 1);如果发散,奖励就趋向于零。这相当于在公式空间上施加了一个平滑性先验。
新颖性奖励 $R_{\text{NOV}}(\alpha)$:防止生成器重新发现池中已有的公式。它等于 1 减去新公式与现有池 $\mathcal{F}_{\text{known}}$ 中任一公式之间的最大绝对 IC:
$$R_{\text{NOV}}(\alpha) = 1 - \max_{\alpha' \in \mathcal{F}_{\text{known}}} |\text{IC}(\alpha, \alpha')|$$与已知公式完全相关的公式新颖性为零;真正原创的公式新颖性接近于一。
带退火(annealing)的复合奖励。三个分量以时变权重 $\lambda(T)$ 和 $\eta(T)$ 组合:
$$R(\alpha,T)=R_{\text{IC}}(\alpha)+\lambda(T)\,R_{\text{SA}}(\alpha)+\eta(T)\,R_{\text{NOV}}(\alpha),\qquad R_{\text{NOV}}(\alpha)=1-\max_{\alpha'\in\mathcal{F}}\bigl|\text{IC}(\alpha,\alpha')\bigr|.$$训练早期,$\lambda(T)$ 较大:结构感知项占主导,即便 IC 接近零(冷启动阶段)也能提供稠密的梯度信号。随着训练推进,$\lambda(T)$ 退火下降,IC 分量接管,于是生成器朝着真正具有预测力的公式收敛。$\eta(T)$ 遵循一个独立的调度——通常随时间上升,以在池被填满时越来越多地惩罚冗余。退火调度是奖励设计的主要超参数;论文中的敏感性分析显示其稳健性中等,但最优调度取决于数据集。
结果
| 市场(测试) | IC | ICIR | AR % | Sharpe |
|---|---|---|---|---|
| CSI300 ('22–'24) | 0.079 | 0.496 | 7.62 | 1.71 |
| CSI500 ('22–'24) | 0.054 | 0.379 | 5.53 | 1.20 |
| S&P500 ('18–'20) | 0.052 | 0.493 | 19.47 | 6.32 |
结果解读
这些标题数字值得仔细解读。在 CSI300 和 CSI500 上,AlphaSAGE 的 IC(0.079、0.054)相对 AlphaForge(0.041、0.053)和 AlphaGen(CSI300 上为 0.058)有扎实的提升,其 Sharpe 比率(1.71、1.20)反映了在充满挑战的 2022--2024 中国股票市场中真实的组合表现。
S&P500 这一行是值得审视的异常值。0.052 的 IC 不算高——与中国市场结果相当——然而报告的 Sharpe 却是 6.32,约为 CSI300 Sharpe 的 4 倍。这种脱节(IC 中等、Sharpe 极高)是有利回测环境的标志:2018--2020 的美国样本包含了 COVID 的剧烈回撤与复苏(2020 年 3--6 月),在那一阶段,横截面动量与均值回复信号在分母横截面离散度很低的情况下产生了超额收益。这一高 Sharpe 几乎可以肯定是特定时期的产物,而非模型的稳定属性。此外,美国测试窗口止于 2020 年,留下六年的样本外历史未经检验。
与基线相比,AlphaSAGE 胜过 AlphaForge(CSI300 上 IC 0.041 / SR 0.88)和 AlphaGen(CSI300 上 IC 0.058 / SR 0.76),也胜过 GP 和 DSO。消融研究将最大的单一提升归因于把 LSTM 编码器替换为 RGCN——结构感知编码的贡献超过了 GFlowNet 采样器或多面奖励各自单独的贡献。这一点值得注意:它表明大部分改进来自对公式空间更好的表示,而不仅仅是更好的搜索算法。
数据集使用 6 个基础特征和 28 个算子。训练与测试时段为 CSI300/500(2010--2024 全样本,测试 2022--2024)和 S&P500(2010--2020,测试 2018--2020)。
局限性
美国市场验证有限。美国数据止于 2020 年——没有后疫情、没有加息周期、没有 2022 年回撤。在一个包含 COVID 的时段上得到的极端 S&P500 Sharpe(6.32),使美国结果难以被解读为持久 alpha 的证据。
计算成本。GFlowNet 训练比朴素的 RL 更昂贵,因为每条轨迹都需要同时评估前向策略 $P_F$ 和后向策略 $P_B$,还要学习配分函数 $Z_\theta$。论文未报告挂钟训练时间,但每次迭代的成本大约是 PPO 基线的 2 倍。
线性组合器。在挖掘出一组多样化的 alpha 之后,组合阶段仍然是对近期最佳表现者的简单线性回归。没有非线性组合器(如 LightGBM、注意力),也没有自适应于市场状态的加权。GFlowNet 采样带来的多样性收益,可能被一个无法利用因子间非线性交互的组合器部分浪费。
缺乏多重检验校正。系统在大量候选公式空间中搜索,却报告未经收缩的原始 IC 和 Sharpe。没有收缩 Sharpe 比率(Deflated Sharpe Ratio),没有 PBO/CSCV,也没有 Harvey-Liu-Zhu 调整(见第 6 讲)。考虑到搜索量之大,所报告的指标是真实样本外表现的上界。
冷启动只是缓解,并未消除。稠密奖励(尤其是 $R_{\text{SA}}$)有助于训练早期,但底层的稀疏性问题是被减轻而非解决——结构感知奖励本身需要一个已被填充的结构邻居池才能计算,这在最初几百次迭代中造成了"先有鸡还是先有蛋"的困境。
退火敏感性。调度 $\lambda(T)$ 和 $\eta(T)$ 控制着探索(结构感知、新颖性)与利用(IC)之间的平衡。论文的敏感性分析显示其稳健性中等,但最优调度取决于数据集,需要针对每个市场进行调参。