核心思想。第一阶段是生成-预测(generative–predictive)挖掘:生成器将噪声映射为一个 公式(在逆波兰表示(Reverse Polish Notation, RPN)矩阵上做 Gumbel-Softmax);一个预测器代理模型在不做昂贵回测的情况下 为公式的适应度(fitness)打分;多样性损失(diversity loss)防止模式坍塌(mode collapse)。第二阶段是动态 组合:每次再平衡按近期 IC/ICIR 筛选因子,并基于近期数据用最小二乘(OLS)重新拟合权重。
为何用学习得到的代理模型而非回测
在 AlphaGen(专题 2)中,每个候选公式都必须被完整评估:计算它在训练窗口内每只股票、每个日期上的横截面取值, 再度量组合池的 IC。该回测是瓶颈——每次评估都要触及整个面板,而 RL 智能体需要 数千个回合(episode)才能收敛。AlphaForge 把这个循环短路了:一个独立的神经网络 $P$ (即"预测器")学会把公式的独热(one-hot)RPN 编码直接映射为其 适应度分数的估计值。一旦 $P$ 在一组(公式,真实适应度)配对的种子集上训练完成,生成器 $G$ 就可以通过 $P$ 做梯度下降优化,而完全不必触碰原始价格数据。评分一个候选公式的代价 从 $O(N_{\text{stocks}} \times T_{\text{days}})$ 降为对一个小网络的一次前向 传播。代价是代理模型会过时:$P$ 是在更早分布的公式上训练的,因此当 $G$ 推进到公式空间中 未被探索的区域时,$P$ 的预测会退化。论文没有在线重训 $P$,这是一个已知的局限。
Gumbel-Softmax:让离散选择可微
公式是一串离散的词元(token)(算子如 ts_cov、操作数如
high、常数如 20)。在每个位置选择一个词元是一次
类别抽样(categorical draw)——而你无法通过 argmax 反向传播梯度。
Gumbel-Softmax 技巧(Jang et al. 2017、Maddison et al. 2017)用一个
连续松弛(continuous relaxation)取代硬性的独热抽样:在 logits 上加入独立同分布的 Gumbel 噪声,再以温度(temperature)
$\tau$ 应用 softmax。当 $\tau$ 较低时,输出趋近于一个独热向量;当 $\tau$ 较高时,输出近乎均匀。
这使 $G$ 能够通过"软"词元选择从 $P$ 获得梯度信号。AlphaForge
在训练过程中对 $\tau$ 做退火(anneal),使早期探索平滑、后期输出
近乎离散。
梯度偏差告诫。Gumbel-Softmax 样本并不是真实离散梯度的 无偏估计量。当 $\tau \to 0$ 时偏差消失但方差爆炸;在任何有限的 $\tau$ 下,梯度大致指向正确方向,但存在系统性偏移。在 实践中这意味着生成器可能收敛到一个在松弛目标下看起来不错、 但在精确离散评估下略次优的公式邻域。论文没有 量化这一差距。
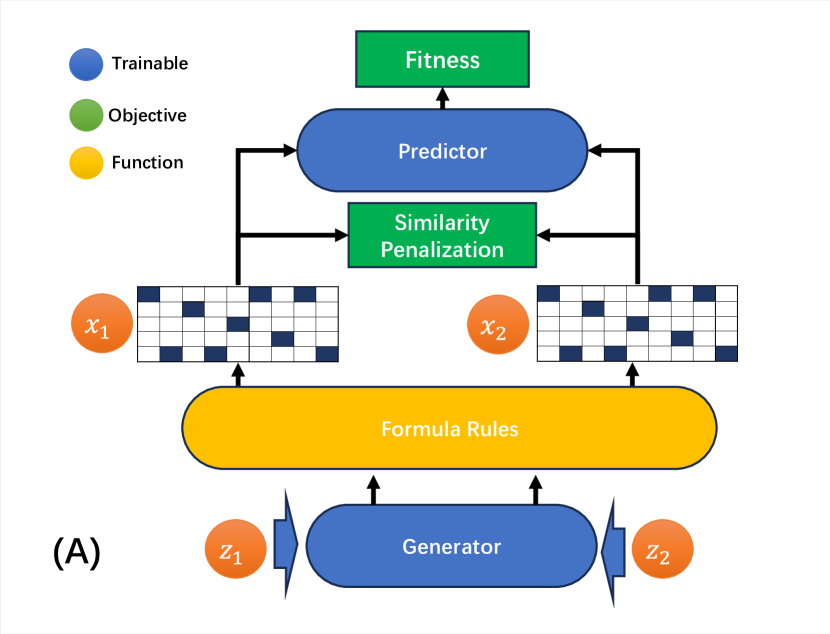
完整的两个阶段
原图展示的是第一阶段。下方示意图补上了第二阶段——即论文贡献真正所系的每日动态组合器。
实例演练:从表达式树到独热 RPN 矩阵
考虑公式 S_log1p(ts_cov(high, volume, 20))。其表达式树的根为
S_log1p,仅有一个子节点 ts_cov,后者又有三个子节点:
high、volume 以及常数 20。一次后序(子节点
先于父节点)遍历得到如下词元序列:
$[\;\texttt{high},\;\texttt{volume},\;\texttt{20},\;\texttt{ts\_cov},\;\texttt{S\_log1p}\;]$
该序列长度为 $S = 5$。设完整词表共有 $D = 40$ 个词元(所有算子、
特征和常数)。RPN 编码是一个矩阵 $\mathbf{X} \in \{0,1\}^{D \times S}$,其中
第 $j$ 列是一个独热向量,指示第 $j$ 个位置上的词元。例如,若
high 的词表索引为 3,则 $X_{3,1} = 1$,第 1 列其余所有元素均
为零。若 ts_cov 的索引为 27,则 $X_{27,4} = 1$。每一列的元素之和恰为一。
较短的公式以一个特殊的 PAD 词元向右填充至最大
序列长度。
在生成过程中,$G$ 并不直接输出一个硬性的独热矩阵。它产生一个 $D \times S$ 的实值 logits 矩阵,再由 Gumbel-Softmax 把每一列转换为近似 独热的向量。预测器 $P$ 以这个(软的或硬的)矩阵为输入,返回一个标量 适应度估计。由于 $P$ 可微、Gumbel-Softmax 也可微,整条 链 $z \to G \to \text{logits} \to \text{Gumbel-Softmax} \to P \to \text{fitness}$ 允许 端到端的梯度计算。
关键数学
每个公式都是一段 RPN 词元序列,编码为独热矩阵 $\mathbf{X}\in\{0,1\}^{D\times S}$。预测器对真实适应度做回归,
$$\mathcal{L}_P=\sqrt{\tfrac{1}{n}\sum_{i=1}^{n}\bigl(P(x_i)-\text{fitness}(x_i)\bigr)^2},$$用文字表述:$\mathcal{L}_P$ 是在 $n$ 个种子公式上,代理模型所预测的适应度与真实适应度(由完整回测度量)之间的 RMSE。最小化它可训练 $P$ 以低成本逼近那昂贵的评估。
生成器则最小化(取负的)预测适应度再加一个多样性项,
$$\mathcal{L}_G=\underbrace{-\,P\bigl(M(G(z))\bigr)}_{\text{fitness}}+\underbrace{\lambda_{\text{oh}}\,\text{Sim}_{\text{oh}}+\lambda_{\text{hid}}\,\text{Sim}_{\text{hid}}}_{\text{diversity}}.$$用文字表述:$G$ 希望产出 $P$ 给高分的公式(故取负号),但当由不同噪声向量 $z_1, z_2$ 生成的两个公式过于相似时则会受到惩罚。
多样性损失:防止模式坍塌
若没有多样性项,$G$ 会收敛到单个高适应度公式,并且无论输入噪声为何都只输出 其微小扰动——这是典型的模式坍塌。多样性 损失由两个互补的相似度惩罚构成,作用于一对由不同噪声抽样生成的公式 $f(z_1), f(z_2)$:
独热相似度($\text{Sim}_{\text{oh}}$)。它度量两个 公式在同一位置选择相同词元的频繁程度。它作用于离散(或 近乎离散)的 RPN 矩阵,捕捉表层的句法重叠。若两个公式 以相同的前三个词元开头,即便后续分叉,$\text{Sim}_{\text{oh}}$ 仍然很高。 可把它视为词元序列上的汉明距离(Hamming distance)代理量。
隐藏相似度($\text{Sim}_{\text{hid}}$)。它度量 $G$ 内部 中间隐藏表示之间的余弦相似度——即最终 logit 投影之前的潜在向量。 两个公式可能逐词元各不相同,但若生成器学会把不同的词元 经由相似的内部路径传递,它们的隐藏状态仍可能近乎相同。 隐藏惩罚捕捉这种更深层的坍塌,而独热惩罚 会遗漏它。
这两项由超参数 $\lambda_{\text{oh}}$ 和 $\lambda_{\text{hid}}$ 加权。 论文未报告对这些权重的敏感性,而把它们设得过高会 为强求多样性而牺牲适应度——这是标准的探索-利用权衡。
适应度还要通过一个与现有因子池 $Z$ 的相关性筛选:
$$\pi(x)=\begin{cases}\bigl|\text{IC}(f,\mathbf{X},\mathbf{Y})\bigr| & f\text{ valid and }\psi(f,Z)<\tau_{\text{corr}}\\[4pt]0 & \text{otherwise.}\end{cases}$$用文字表述:一个生成的公式只有在满足以下两点时才获得非零适应度分数:(a) 它能解析为一个有效的 表达式;(b) 它与因子池中已有的每个公式的横截面收益相关性 都低于阈值 $\tau_{\text{corr}}$。否则适应度被设为零。这一硬性门槛防止因子池被同一信号的冗余、高度相关的变体填满。
深入剖析动态组合器
固定权重 vs. 动态因子集组合
AlphaGen(专题 2)挖掘一个因子池,并在训练时固定组合权重:OLS 权重在训练窗口上一次性求解,随后原封不动地应用于样本外。若某个 因子衰减或出现新的市场状态(regime),这些权重就过时了。AlphaForge 的改进 不是一个更精巧的加权器(它仍是普通 OLS,没有收缩、岭回归(ridge) 或弹性网(elastic-net)正则化)。改进在于进入 回归的因子集合每天都在变化。一个上个月有用、但近期 IC 已 跌破阈值 $\text{IC}'$ 的因子会被悄然剔除,而另一个 IC 上升的因子 会顶替它的位置。因此其自适应性是需求侧的(选择哪些因子), 而非供给侧的(如何加权)。
这一设计有一个微妙的后果:OLS 权重 $\mathbf{w}_t^*$ 仅用在时刻 $t$ 通过 IC/ICIR 筛选而存活下来的因子,在近期窗口上重新估计。由于 因子集合在变,某个给定因子 $f_j$ 的权重可能从某一天到 下一天跳变不连续——并非因为加权器改了主意,而是因为回归的 构成变了(不同的回归元会改变所有人的 OLS 解)。这 引入了论文未加度量的隐性换手率(turnover)。
IC/ICIR 门槛:它的作用及风险
阈值 $\text{IC}'$ 和 $\text{ICIR}'$ 是第一道防线:任何近期 IC 或近期 ICIR 跌破这些值的因子都会在 OLS 步骤之前被剔除。$\text{IC}'$ 筛选最低预测水平;$\text{ICIR}'$ 筛选最低一致性(一个平均 IC 高 但逐日剧烈波动的因子并不可靠)。论文报告了 每日 $N = 10$ 个活跃因子的最优值(由消融实验确定),但 $\text{IC}'$ 和 $\text{ICIR}'$ 被当作固定超参数,既不学习也不自适应。这是一个风险: 在低波动状态下许多因子可能都能过关(对噪声过拟合);在 高波动状态下少有因子能存活(欠拟合,使模型近乎为空)。 一个随状态自适应的阈值,或一个基于滚动分位数的门槛,将是自然的扩展。
结果
| IC / RankIC (%, ±std) | CSI300 IC | CSI300 RankIC | CSI500 IC | CSI500 RankIC |
|---|---|---|---|---|
| AlphaForge | 4.40 (0.56) | 5.89 (0.69) | 2.84 (0.58) | 5.57 (0.58) |
| RL(AlphaGen 风格) | 2.09 | 2.72 | 1.91 | 4.03 |
| DSO | 2.55 | 3.88 | 1.38 | 4.56 |
| GP | 1.29 | 2.72 | 0.37 | 2.34 |
解读这些数字
表中所有 IC 值都以百分点为单位——例如, AlphaForge 在 CSI300 上 4.40 的 IC 意味着绝对值 $\overline{\text{IC}} = 0.044$。 作个参照:在中国 A 股市场,0.05 的 IC 对一个每日横截面预测器而言已算很强, 那里散户参与度高、定价效率较低,因而比美国大盘股 提供更多的 alpha 机会。这些标准差(CSI300 IC 为 0.56) 是跨 5 个随机种子的,而非跨时间;它们反映的是挖掘 过程的逐次运行变异性,而非信号的逐日波动性。
AlphaForge 在 CSI300 上大致把 RL 基线的 IC 翻了一番(4.40 对 2.09 个百分 点)。在 CSI500 上提升较窄(2.84 对 1.91),这表明代理模型 + 动态组合器的方法在一个集中的大盘股票池(300 只)中增值更多, 那里因子相互作用更有结构,而在更广、更嘈杂的 500 只股票 池中增值较少。
实盘交易告诫
论文报告了一个用 300 万元人民币资本交易 CSI500 成分股的实盘账户, 在约 9 个月内取得 21.68% 的超额收益。这是一次在小账户上、 未经复现的单次试验。有若干理由对其打折扣:(a) 单个 9 个月的窗口很 容易恰好碰上一个有利的市场状态;(b) 该收益未扣除任何交易成本 或市场冲击,而这些在每日再平衡频率下并非微不足道;(c) 300 万元小到 市场冲击可忽略,因此该结果说明不了容量问题;(d) 没有 一个换手率相同、同期可作公平比较的基准策略。该 实盘结果作为一次部署验证(proof-of-deployment)是有趣的,但作为 alpha 的证据,其统计 权重基本为零。
局限
组合器过于简单。组合器是普通 OLS,没有状态感知、没有 收缩、也没有正则化。在一个 300 多只股票、仅有 $N = 10$ 个因子的股票池中, OLS 的条件数不算太差,但它对存活因子之间的 多重共线性,或对因子载荷的结构性断裂,都无任何防护。
固定门槛。IC 和 ICIR 阈值($\text{IC}', \text{ICIR}'$)是 在验证集上通过网格搜索选定的固定超参数。它们不随变化的 市场条件而自适应,这意味着活跃因子的有效数量可能视市场状态而 缩至近零或扩至整个因子池——两个极端都不可取。
Gumbel-Softmax 偏差。如上所述,连续松弛在任何有限温度下都会引入 系统性的梯度偏差。没有任何理论收敛 保证生成器能到达离散目标的全局最优。
代理模型衰减。预测器 $P$ 在初始种子集上训练一次后即 冻结。随着生成器探索新的公式族,$P$ 的精度退化——它是 在其训练分布之外做外推。一个在线再校准循环(周期性地 用真实适应度函数评估一批 $G$ 的输出并微调 $P$)可以 缓解这一点,但论文未实现。
缺乏防过拟合方法学。与这一谱系中所有其他系统一样,
AlphaForge 不报告紧缩夏普比率(Deflated Sharpe Ratio),不运行 PBO/CSCV,也不应用
Harvey-Liu-Zhu 多重检验校正。挖掘阶段评估了数千个候选
公式;在不知道这么多无技能试验所预期的最佳夏普的情况下,所报告的 0.88 夏普
(CSI300,依 AlphaSAGE 的对比表)并无信息量。年度重训的
留出集(train_end_year)是单次时间序列切分,而非净化(purged)滚动前推(walk-forward)
交叉验证——它对演示足够,但对一个可发表的 alpha 主张
则不足(见专题 6)。
因子池规模。消融实验给出的最优池为 $N = 10$ 个活跃因子。该 框架能否扩展到 50 或 100 个因子——以及 OLS 组合器在 那种规模下能否保持稳定——尚未探究。