AlphaEvolve (2021) — 在表达式树(expression tree)上的演化式 AutoML
名称撞车。 Google DeepMind 在 2025 年 5 月发布了一套与此无关、但也叫 "AlphaEvolve"
的系统(一个由 Gemini 驱动的演化式编程智能体)。在本讲中,AlphaEvolve 始终指
2021 年 Cui 等人的量化阿尔法论文。
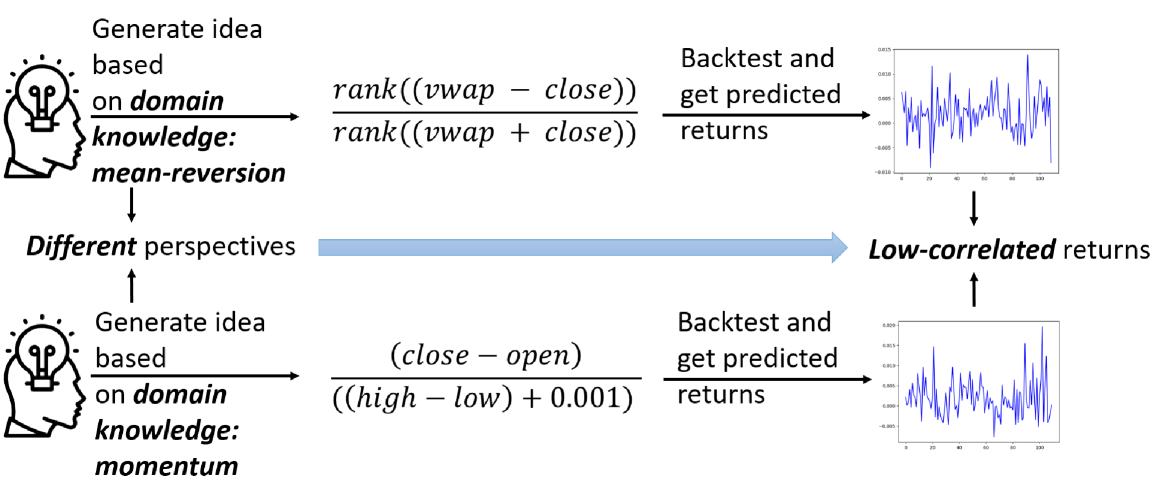
核心思想。 把阿尔法定义为跨三类算子的程序——标量(scalar)、向量
(vector,横截面)和矩阵(matrix,关系型)——严格地比标量公式化阿尔法(formulaic alpha)更丰富,
却仍可作为弱相关的因子集合被挖掘。一个演化式搜索(锦标赛选择(tournament selection)、变异(mutation)、
相关性剪枝(correlation pruning))探索这一扩展空间,其中的剪枝加速器在消融实验中被证明可带来约 10×
的搜索效率提升。
标量 / 向量 / 矩阵算子分类
传统的公式化阿尔法(例如 WorldQuant 风格的 "Alpha#101" 表达式)完全由
标量算子(scalar operators)构成:这些函数接收单只股票的一条或多条时间序列,
并为该股票返回单条时间序列。例子包括 log(close)、
ts_mean(volume, 20)(过去 20 日均值)、rank(close/open)
以及 ts_delta(high, 5)。它们逐只股票运算;每只股票的阿尔法都是
独立计算的。
AlphaEvolve 增加了两类更丰富的算子。向量算子(vector operators)在横截面上运算:
它们接收给定日期上所有股票的阿尔法值,并返回一个变换后的横截面。
具体例子有 cs_rank(横截面分位排名)、
cs_zscore(横截面 z-score)以及 sector_neutralize
(减去行业均值)。这些算子使得诸如"在当前行业内部的 5 日动量排名"这类相对价值
表达式成为可能,而这在纯标量语法中是无法实现的。
矩阵算子(matrix operators)更进一步:它们引入了连接股票之间的显式关系结构
(一个邻接矩阵或权重矩阵)。例如,一个矩阵算子可以将横截面阿尔法向量
乘以一个行业邻接矩阵,从而为每只股票生成其相关同行阿尔法值的加权平均。
这允许诸如"供应链邻居的动量"或"相对行业 ETF 的强弱"这类表达式。关键区别在于,矩阵算子需要一个外部
关系矩阵 $\mathbf{R} \in \mathbb{R}^{N \times N}$ 作为输入,而标量算子与向量算子
在 OHLCV 数据内部是自足的。
为何表达式树程序比标量公式化阿尔法更丰富
标量公式化阿尔法是一个对每只股票独立求值的单一代数表达式。
AlphaEvolve 将每个阿尔法表示为一棵表达式树(expression tree)(一个程序),其内部节点
是来自上述三类中任意一类的算子,叶子节点则是市场特征(开盘价、最高价、最低价、
收盘价、成交量)或常数。由于标量、向量和矩阵算子可以在树内自由组合,
单个程序就能表达多步逻辑:先计算每只股票的动量
信号(标量),再在横截面上对其排名(向量),然后通过行业
图扩散(矩阵)。这种组合深度严格超出了纯标量语法的能力范围,
后者在任何节点都无法引用横截面或关系结构。
架构
初始阿尔法池基于标量 / 向量 / 矩阵算子的表达式树
↓
锦标赛选择 → 变异算子替换 · 操作数更改 · 子树插入/删除
↓
有效性 + 哈希去重 → 适应度 (IC)在验证集上评估
↓
相关性剪枝 → 更新后的池若与池的 $|\rho|$ $> \tau_{\text{corr}}$ 则丢弃;重复 $G$ 代
锦标赛选择与变异如何进行
在每一代中,从当前阿尔法种群里随机抽取一个小的子集(即"锦标赛")。
该子集中适应度(IC)最高的阿尔法被选为父代。
锦标赛选择在不需要对整个种群进行全局排序的情况下,引入了偏向高适应度个体的选择压力,
从而保持每一代的计算成本较低。
被选中的父代随后通过三种算子之一进行变异,每种以
概率 $p_m$ 应用:
- 算子替换:随机选取的某个内部节点的算子被替换为另一个
具有相同元数(arity)和类型类别的有效算子(例如
ts_mean 替换为
ts_std,二者都是标量一元时间序列算子)。
- 操作数更改:某个叶子节点的特征被切换(例如
close
替换为 volume),或某个常数被扰动。
- 子树插入 / 删除:随机选取的子树要么被替换为
新生成的随机子树(插入),要么被剪除并替换为单个叶子(删除)。
这控制了表达式复杂度,并允许跳跃到结构上不同的程序。
变异之后,有效性检查(算子输入的类型一致性、无除零、输出有限)
与基于哈希的去重(拒绝其表达式树哈希与某个已评估程序相同的阿尔法)会
在适应度评估之前过滤掉畸形或冗余的候选。
相关性剪枝及其约 10 倍的效率提升
在适应度评估之后,一个新生成的阿尔法只有当它与每个现有池成员之间的最大
绝对成对 Pearson 相关性低于阈值
$\tau_{\text{corr}}$(通常约为 0.15)时,才被纳入池中。那些通过了 IC 过滤、但
与某个现有信号的信息含量重复的阿尔法会被立即丢弃。
消融研究表明,在没有相关性剪枝的情况下,演化式搜索会把
绝大部分计算预算浪费在重新发现已知信号的细微变体上。
在剪枝启用后,每个存活下来的阿尔法都被迫占据收益预测空间中
一个不同的区域,因此搜索前沿每一代大约扩展快 10 倍。
其直觉很直接:在高维算子空间中,许多语法上不同的
程序会产生几乎相同的横截面输出。剪枝在早期就压缩了这种冗余,
把变异导向真正新颖的信号。
可借鉴之处。 相关性剪枝是现代阿尔法流水线中多样性控制
的直接前身。在生产中,维持一个低相关的因子池等价于
强制要求每个新信号都为组合组合投资带来边际解释力。
同样的原则也出现在分层风险平价(对相关因子聚类)以及
AlphaGen 的协同奖励(见下文第 2 节)中。阈值 $\tau_{\text{corr}}$ 是一个
在池规模与多样性之间权衡的超参数;过低则很少有阿尔法存活,过
高则池会退化为共线噪声。
关系知识注入:威力与局限
矩阵算子需要一个预先指定的关系矩阵 $\mathbf{R}$——例如一个二值的
行业共属矩阵、一个供应链链接图,或一个滚动相关性矩阵。
这正是 Cui 等人所称的"关系知识注入":领域专业知识被编码为一个
固定的图,演化式搜索去发现如何使用它(应用哪个矩阵算子、
在树的哪个深度、与哪些标量/向量变换组合)。
其局限在于关系结构本身是人工设计的,而非学习得到的。
系统无法发现某个新颖的关系(例如共享分析师覆盖、来自 10-K 文件的
客户—供应商链接)会具有信息量;它只能利用设计者
预先指定的关系。这是一个显著的瓶颈:矩阵算子类别的丰富程度
受限于搭建搜索的人的想象力与数据获取能力。后来的系统
(基于 GNN 的方法、由 LLM 驱动的智能体)尝试从数据中学习关系结构,但
代价是可解释性。
关键数学
适应度是平均横截面信息系数(Information Coefficient, IC),
$$\text{IC}(f) = \frac{1}{T}\sum_{t=1}^{T}\rho\bigl(f(\mathbf{X}_t),\,\mathbf{y}_t\bigr),$$
用通俗的话说:对每个交易日 $t$,计算阿尔法的
横截面得分 $f(\mathbf{X}_t)$(每只股票一个数)与已实现的未来收益
$\mathbf{y}_t$ 之间的 Pearson 相关性。再把这个每日相关性在 $T$ 天上取平均。IC 越高意味着阿尔法
对股票的排序越接近实际后续收益的排序。
而一个新阿尔法只有当它与现有池 $\mathcal{F}$ 充分去相关时才被保留:
$$\max_{f_j\in\mathcal{F}}\bigl|\rho(f_{\text{new}},f_j)\bigr| < \tau_{\text{corr}}.$$
用通俗的话说:取新阿尔法的每日横截面输出,并将其与
池中已有的每个阿尔法做相关。如果最高的绝对相关性超过 $\tau_{\text{corr}}$,
则新阿尔法与某个已知信号过于相似,被丢弃。这道硬性门槛
强制每个池成员都携带真正独立的信息。
结果与局限
数据集与范围。 美股(NYSE/NASDAQ,2013--2017,约 1,026 只名称)。
该系统发现的阿尔法具有较高的夏普比率(Sharpe ratio),且成对相关性低于约 15%,
展示了相关性剪枝在维持池多样性方面的有效性。
具体的 IC 与夏普数值并未被显著地列表呈现;论文强调的是
相对于标准 GP 基线的多样性—效率权衡,而非绝对的
预测幅度。
值得内化的局限:
- 无梯度的纯演化式搜索难以扩展到非常大的算子空间;
每次适应度评估都需要一次完整的横截面回测。
- 矩阵算子显著增加了计算成本(在每次评估时对
$N \times N$ 关系做矩阵乘法)。
- 没有组合模型:阿尔法被单独挖掘并事后拼装,这意味着
搜索得不到来自下游组合的反馈。
- 关系领域知识是人工设计的,而非从数据中学习得到的。
- 没有抗过拟合方法:没有缩减夏普比率(Deflated Sharpe Ratio)、没有 PBO、没有走步外推(walk-forward)净化。
鉴于搜索会评估数千个候选程序,所报告的指标
易受选择偏差影响。
- 仅在美股上测试;没有跨市场验证。
AlphaGen (2023) — 用 RL/PPO 生成协同的公式集合
核心思想。 不要再一次只挖一个阿尔法。让 RL 的奖励等于
组合因子池的 IC,而非单个阿尔法的 IC——这样策略学到的是能改进
整体集成的因子。协同(synergistic)成为目标本身,而非事后补救,从而构建出一条从
组合器回到生成器的反馈回路。
为何优化组合池 IC 胜过单独挖掘阿尔法
传统的阿尔法挖掘(包括 AlphaEvolve)按每个候选公式的独立 IC 来评估它。
最优的单个阿尔法被收集起来,然后用等权或优化权重事后组合。
问题在于:两个各自都很强的阿尔法之间可能高度相关,组合时
几乎不贡献边际信息。反之,一个 IC 一般、但
与现有池不相关的阿尔法,却可能大幅提升组合的预测能力。
独立 IC 排名对这种互补性是盲目的。
AlphaGen 通过让 RL 奖励等于组合线性模型
$\hat{y} = \sum_j w_j f_j(\mathbf{X})$ 的 IC(而非新生成的 $f_{\text{new}}$ 单独的 IC)来解决这一问题。
因此,当某个阿尔法被加入
现有池并由 OLS 重新加权后,若能产生比没有它的池更好的集成预测,策略网络就会获得更高的奖励。
这之所以"协同",是因为生成器被直接激励去填补
池在收益预测空间覆盖上的空缺。一个重复现有
信息的高 IC 阿尔法只获得低奖励;一个与池正交的中等 IC 阿尔法则获得高
奖励。这条反馈回路弥合了 AlphaEvolve 留下的搜索与组合之间的鸿沟。
可借鉴之处。 协同奖励原则可直接映射到现代 ML 阿尔法体系中的
面向组合的训练(portfolio-aware training)。任何把信号
孤立训练、之后再组合的系统,都在白白放弃分散化价值。
实务实现:在评估某个候选信号时,衡量它对
现有持仓的 IC 或夏普的边际贡献,而非它的独立得分。这等价于在
针对现有因子做残差化之后评估该信号的 IC。
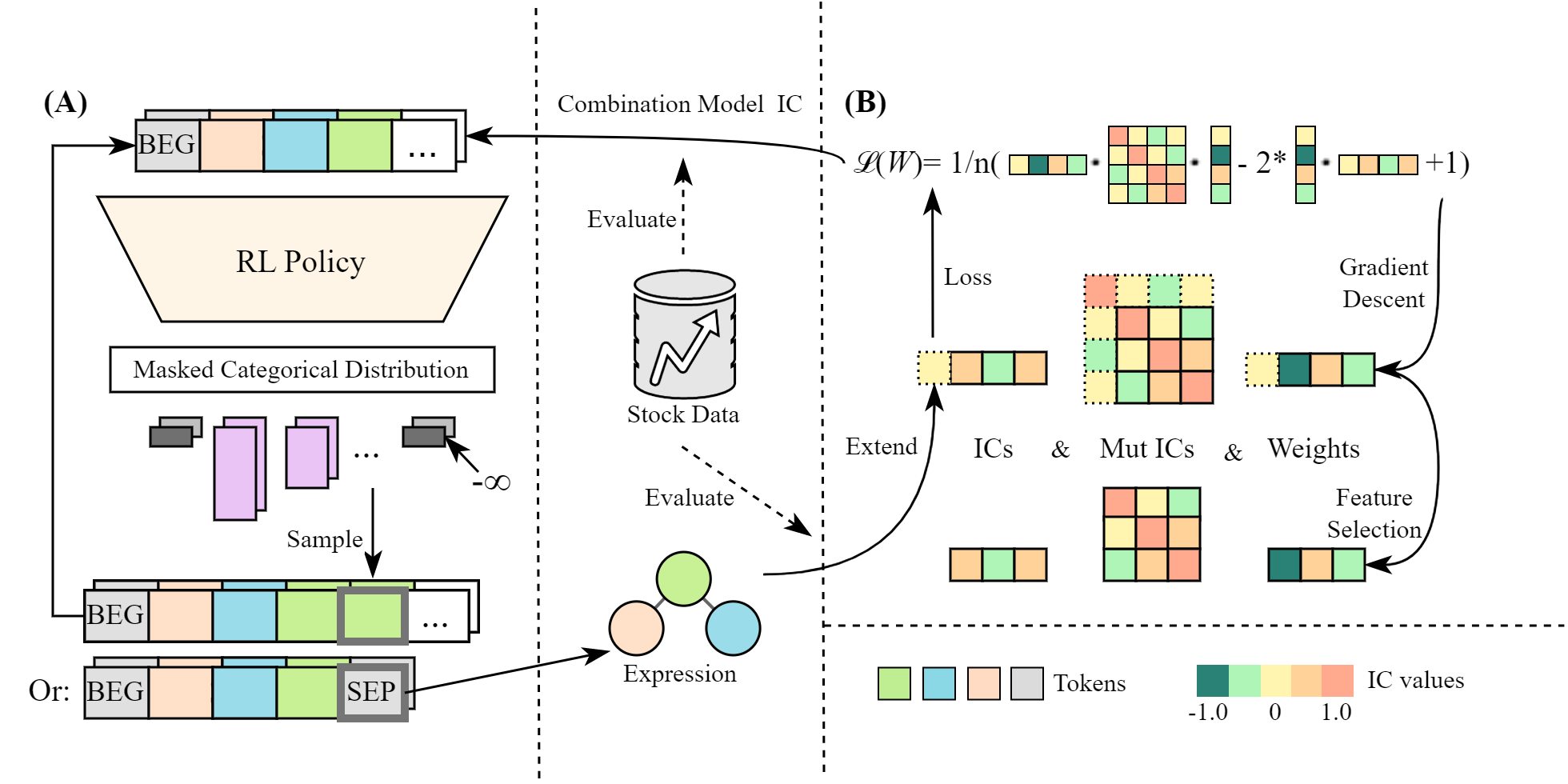
架构
LSTM 策略(噪声 → 词元)2 层,128 隐藏单元;输出 RPN 词元序列(≤ 20 个词元)
↓
有效性过滤 → 新阿尔法 $f_{\text{new}}$RPN 语法约束
↓
线性组合模型$\hat{y}=\sum_j w_j f_j(\mathbf{X})$,OLS 权重,top-$k$ 池
↓
奖励 = 组合输出的 IC → PPO反向传播至策略
LSTM 策略网络有 2 层、128 个隐藏单元,外加分离的策略头与价值头
(各为一个含 64 个隐藏单元的 2 层 MLP)。在每一步,策略以
迄今为止的部分序列为条件,从有效 RPN 算子与操作数的词表中采样一个词元,直到
输出一个 SEP(分隔符)词元或达到 20 词元上限。语法约束
(对 RPN 的栈深度检查)确保每段输出序列都能解码为一棵良构的表达式
树。组合模型是对池中 top-$k$ 个阿尔法做的一个简单 OLS 线性回归;
当加入新阿尔法且池超出容量时,绝对 OLS 权重
最小的那个阿尔法被丢弃。
关键数学
用通俗语言解释 PPO 目标
生成器用裁剪式 PPO(近端策略优化(PPO))目标进行训练
$$\mathcal{L}^{\text{CLIP}}(\theta)=\hat{\mathbb{E}}_t\Bigl[\min\bigl\{r_t(\theta)\hat A_t,\;\text{clip}(r_t(\theta),1-\epsilon,1+\epsilon)\hat A_t\bigr\}\Bigr],\quad r_t(\theta)=\frac{\pi_\theta(a_t\mid s_t)}{\pi_{\theta_{\text{old}}}(a_t\mid s_t)}.$$
各项的作用。 比率 $r_t(\theta)$ 衡量当前策略 $\pi_\theta$
采取动作 $a_t$ 的可能性,相比采集数据的旧策略 $\pi_{\theta_{\text{old}}}$
增大(或减小)了多少。如果策略自数据采集以来变化很大,$r_t$ 就会
远离 1。优势函数(advantage) $\hat{A}_t$ 估计该动作的结果比预期
更好还是更差:正优势意味着"该动作带来了高于平均的组合池 IC",
负优势意味着"该动作损害了整体集成"。乘积 $r_t \hat{A}_t$ 推动
策略增大具有正优势的动作的概率,并减小具有
负优势的动作的概率。
裁剪 $\text{clip}(r_t, 1-\epsilon, 1+\epsilon)$ 是稳定性机制。
若没有它,单个高优势动作就可能引发巨大的策略更新,使训练失稳。
取裁剪项与未裁剪项的 $\min$ 确保当 $r_t$ 偏离 1 过远
(策略变化过大)时,梯度被置零。典型取 $\epsilon = 0.2$,意味着
每次更新的策略比率被限制在 0.8 到 1.2 之间。这使 RL 训练在
探索公式空间所需的数千个回合中保持稳定。
定理 3.1:支持增量更新的分解
他们的定理 3.1 将组合损失分解,使其能以 $O(k^2)$ 复杂度更新:
$$\mathcal{L}(\mathbf{w})=\frac{1}{n}\Bigl(1-2\sum_{i=1}^{k}w_i\,\bar\sigma_y(f_i)+\sum_{i,j=1}^{k}w_i w_j\,\bar\sigma(f_i,f_j)\Bigr),$$
其中 $\bar\sigma_y(f_i)$ 是 $f_i$ 与收益的时间平均相关性(即它的 IC),
$\bar\sigma(f_i,f_j)$ 是平均成对相关性。回合奖励就是协同目标
$r=\bar\sigma_y\!\left(\sum_i w_i f_i\right)$。
这个分解为何重要。 朴素地看,每当往池中加入一个新阿尔法,
你都需要从头重新计算整个组合模型:在全部 $N$ 只股票和 $T$ 个日期上
重新评估所有 $k$ 个阿尔法、重新拟合 OLS、并重新计算组合 IC。在约 1,000 只股票、约 1,000 个
交易日、以及一个含 $k$ 个阿尔法的池的情况下,每次加入的成本是 $O(NTk)$——当 RL 智能体
在每次训练中生成数千个候选阿尔法时,这非常昂贵。
定理 3.1 表明,组合损失只依赖于两组可预先计算的汇总
统计量:(i) $k$ 个单独 IC $\bar\sigma_y(f_i)$(每个阿尔法与收益的时间平均
相关性),以及 (ii) $k \times k$ 的成对相关性矩阵 $\bar\sigma(f_i, f_j)$。
当一个新阿尔法 $f_{k+1}$ 到来时,你只需计算 $k+1$ 个新数:它的 IC
$\bar\sigma_y(f_{k+1})$ 以及它与各阿尔法的 $k$ 个成对相关性 $\bar\sigma(f_{k+1}, f_j)$,
$j = 1, \ldots, k$。随后即可从扩展后的 $(k+1) \times (k+1)$
相关性矩阵更新 OLS 权重。总增量成本:矩阵运算的 $O(k^2)$ 加上
计算新阿尔法横截面值的 $O(NT)$(这无论如何都必须做)。这使得
奖励信号足够廉价,可作为每个回合都计算的 RL 奖励。
解读结果
IC 0.0725 在实践中意味着什么。 CSI300 上 0.0725 的 IC 意味着,在
平均的一个交易日里,组合阿尔法的横截面股票
得分与随后已实现收益之间的 Pearson 相关性约为 7.25%。在中国
A 股中,这是一个有意义的信号:经验上,该市场中 IC 高于约 0.03 即被视为可交易,0.07 以上
按横截面标准已属强劲。作为对照,单个广为人知的因子(例如 20 日
动量)通常给出 0.02--0.04 区间的 IC;AlphaGen 的组合池几乎将其
翻倍。相对 XGBoost(0.0404)的提升表明,协同式公式组合方法
捕捉到了单个在原始特征上训练的非线性模型所捕捉不到的结构。
为何 RankIC 与 IC 不同。 IC 对原始阿尔法得分
和原始收益使用 Pearson 相关性;它对异常值以及两个变量的分布形态都很敏感。
RankIC(Spearman 相关性)先在横截面上对阿尔法得分和收益分别排名,
再对排名做相关。这使 RankIC 对非线性和极端值具有稳健性。
实践中,RankIC 往往高于 IC(如本表中 CSI300 上 0.0806 vs. 0.0725),
因为阿尔法的排序能力优于其预测收益确切
幅度的能力。对于组合构建(多空十分位组合),RankIC 可以说是
更具决策相关性的指标,因为交易信号是"该超配哪些股票"(一个
排序问题),而非"每只股票将跑赢多少个基点"(一个回归问题)。
CSI300 对比 CSI500。 AlphaGen 的 IC 从 0.0725(CSI300,大盘)下降到 0.0438
(CSI500,中盘)。这与中盘股更高的噪声和更低的分析师覆盖一致,
使得横截面预测更困难。GP 基线在 CSI500 上崩塌到 0.0117,
表明独立的公式化搜索在噪声更大的股票池中尤其脆弱——
而这恰恰正是协同组合贡献最大价值的地方。
在 CSI300 上(2020--2021)使用 top-50/drop-5 策略的回测显示出相对基线最高的累计
净值(以图形方式报告;未提供列表化的夏普比率)。
局限
局限要点。 $O(k^2)$ 的成对成本把池上限压在几十个;仅优化 IC
(无夏普/换手率/回撤);仅限中国 A 股;固定的线性组合器;没有走步外推净化
或夏普缩减。第 3 讲的动态组合正是对此的直接回应。
- $O(k^2)$ 的成对相关性计算把实际可用的池规模限制在几十个
阿尔法。超过约 50 个之后,OLS 的矩阵求逆在数值上变得脆弱,且每回合
计算所有成对相关性的成本以平方增长。
- 目标是纯 IC——没有对高换手率的惩罚、没有回撤约束,
也没有交易成本模型。一个 IC 为 0.07 但日换手率达 80% 的组合阿尔法,
在计入成本后可能无法交易。
- 组合模型是一个固定的线性回归。阿尔法之间的非线性交互
(例如动量只在低波动率体制下有效)对组合器是不可见的,
因而对奖励信号也是不可见的。
- 没有抗过拟合控制:没有缩减夏普比率、没有走步外推净化、没有
多重检验校正。RL 智能体评估数千个候选公式;
所报告的 IC 是找到的最优池,并未对尝试了多少个池做校正。
- 仅在中国 A 股(CSI300/CSI500)上测试。能否迁移到微观结构与
信息环境差异巨大的美股或欧股市场,尚属未知。
可借鉴之处。 协同奖励——按每个新信号
对组合 IC 的边际贡献、而非其独立优劣来评估它——是本文中
最具可迁移性的单一思想。在现代阿尔法体系中,这转化为按
候选信号在投出现有持仓后的残差 IC(residual IC)来打分,或者
等价地按组合模型样本外 $R^2$ 的改进来打分。定理 3.1
的分解提供了一个高效方案:维护一个滚动的成对相关性矩阵和
一个各信号 IC 的向量;当新信号到来时,只需计算 $k$ 个新相关性和
一个新 IC,即可决定是否纳入它。