RD-Agent(Q) — 自主因子-模型联合优化(autonomous factor–model co-optimization)
核心思想。这是首个由大语言模型(LLM)智能体驱动、在一个闭环(closed loop)中同时优化
因子挖掘(factor mining)与模型架构(model architecture)的系统。它并不在固定语法
(fixed grammar)中搜索——而是编写任意 Python 因子代码,从而极大地扩展了搜索空间。一个上下文老虎机
(contextual bandit)在每一轮决定:是把精力投入因子还是模型。
为何自由形式代码极大地扩展了搜索空间
Topics 1-4 中的每个系统都把 alpha 公式约束在一套固定语法(fixed grammar)内:一组预先确定的算子
(如 ts_mean、rank、log)作用于一组预先确定的特征(如 OHLCV),
再组合成深度有界的表达式树(expression tree)。这一搜索空间尽管在组合意义上极为庞大,但对给定的深度上限而言
终究是有限且可枚举的。RD-Agent(Q) 完全抛弃了这一约束。由于大语言模型(LLM)生成的是任意 Python 函数,
因子可以包含条件逻辑、循环、对 NumPy/Pandas 的调用、滚动回归、依赖市场状态(regime)的分支,或任何其他可在
图灵完备(Turing-complete)语言中表达的构造。搜索空间从"$k$ 个算子上深度 $\le d$ 的所有表达式树"跃升为
"大语言模型能写出的所有程序"——这个空间不仅更大,而且在性质上根本不同,因为它包含了在任何固定算子语法中
都无法表示的因子。其代价是:这种开放式空间使系统性覆盖(systematic coverage)成为不可能;系统完全
依赖于大语言模型对"哪些金融计算可能富含信息"的先验(priors),这既带来了优势(富有创意、非显而易见的因子),
也带来了首要弱点(大语言模型的训练语料决定了它能提出什么的边界)。
架构——五个单元
Specification上下文 $S=(B,D,F,M)$——背景、数据、输出格式、环境
↓
Synthesis (LLM)$h^{(t+1)}=G(\mathcal{H}_t^{(a)},\mathcal{F}_t^{(a)})$——从过往轨迹与反馈生成新假设(hypothesis)
↓
Co-STEER implementationDAG 任务调度 → 带知识检索的代码生成 → 在 Qlib 中运行
↓
Validation相关性去重($|\text{IC}|\ge0.99$)+ 用 SOTA 模型回测该因子(反之亦然)
↓
Analysis → Thompson sampling8 维状态;选择下一臂:探索因子还是模型?
逐一走过这五个单元
1. 规格说明(Specification)。在任何生成开始之前,先装配一个上下文元组
$S = (B, D, F, M)$:$B$ 是描述预测任务的自然语言背景(如"预测 CSI300 次日横截面收益");$D$ 定义
数据接口(可用列、日期范围、频率);$F$ 规定因子必须遵循的输出格式(每只股票、每个日期的得分);$M$ 描述
执行环境(Qlib 回测配置、股票池、成本假设)。该元组锚定了所有下游大语言模型(LLM)提示,使生成的代码无需
人工编辑即可与执行框架兼容。
2. 综合生成(Synthesis)。大语言模型(LLM)在被选中的任一臂 $a$(因子或模型)上,
以先前假设的完整轨迹 $\mathcal{H}_t^{(a)}$ 及其反馈 $\mathcal{F}_t^{(a)}$ 为条件,产生一个新假设
(hypothesis)$h^{(t+1)}$。通俗地说:大语言模型回读它之前尝试过什么、什么有效、什么失败以及为何失败,然后
提出新的东西。这正是该循环在多次迭代中积累知识、而非生成相互独立抽样的机制。
3. Co-STEER 实现。假设被分解为一个由子任务构成的有向无环图(directed acyclic graph,
DAG),并按复杂度得分 $\alpha_j$ 排序。每个子任务通过 $c_j = I(t_j, c_{\text{ref}}, K)$ 实现:大语言模型
在参考代码 $c_{\text{ref}}$ 与一个检索得到的、记录以往成功实现的知识库 $K$ 的引导下,为任务 $t_j$ 编写代码
$c_j$。DAG 结构意味着相互独立的子任务(如计算两个不相关的特征)可以并行执行,而相互依赖的子任务(如某特征
需要另一特征的输出)则遵循拓扑顺序。这对效率至关重要:单个因子假设可能涉及多个中间计算,而朴素的顺序执行会
浪费时间。
4. 验证(Validation)。运行两项检查。第一,去重过滤器:若新因子与任何已有因子的横截面
信息系数(Information Coefficient, IC)绝对值超过 0.99,则被标记为冗余并丢弃。这一阈值刻意接近完美相关——
目的仅在于捕捉那些在重新缩放下本质相同的因子,而非更广泛地强制多样性。第二,因子被联合评估:新因子用当前最优
模型测试,新模型用当前最优因子集测试,从而使任一臂的改进总是在另一臂的背景下加以衡量。
5. 分析(Analysis)。系统必须决定下一步做什么:大语言模型应当尝试发现更好的因子,还是
重新设计预测模型?这被形式化为一个双臂上下文老虎机(contextual bandit),详见下文。
上下文汤普森采样老虎机(the contextual Thompson-sampling bandit)
该老虎机面对两个臂——$a \in \{\text{factor}, \text{model}\}$——必须把下一轮大语言模型(LLM)的努力
分配给更可能提升整体表现的那一臂。该决策之所以是上下文的(contextual),是因为最优臂取决于系统当前位于
表现空间中的何处。
上下文是一个总结当前表现的 8 维状态向量:
$$\mathbf{x}_t=[\text{IC},\,\text{ICIR},\,\text{RankIC},\,\text{RankICIR},\,\text{ARR},\,\text{IR},\,-\text{MDD},\,\text{SR}]^\top.$$
用文字说:这八个数字既刻画了因子集的预测质量(IC、ICIR、RankIC、RankICIR),也刻画了组合层面的结果
(年化收益、信息比率(Information Ratio, IR)、负的最大回撤、夏普比率)。这里用负的 MDD,是为了让所有
分量都"越高越好"。该状态告诉老虎机,例如"IC 还不错但夏普偏低"——这可能暗示瓶颈在模型(组合构建步骤)而非
因子。
每个臂 $a$ 维护一个贝叶斯线性模型:在状态 $\mathbf{x}_t$ 下选择臂 $a$ 的期望奖励为
$r^{(a)} = (\theta^{(a)})^\top \mathbf{x}_t$,其中 $\theta^{(a)} \in \mathbb{R}^8$ 是一个未知权重向量。
系统对每个臂的权重维护一个高斯后验 $\theta^{(a)} \sim \mathcal{N}(\mu^{(a)}, (P^{(a)})^{-1})$。在每一轮,
汤普森采样(Thompson sampling)从当前后验中抽取一个样本 $\tilde{\theta}^{(a)}$,为每个臂计算预测奖励
$\hat{r}^{(a)} = (\tilde{\theta}^{(a)})^\top \mathbf{x}_t$,并选取抽样值较高的那个臂:
对臂 $a\in\{\text{factor},\text{model}\}$ 进行汤普森采样(Thompson sampling):抽取 $\tilde\theta^{(a)}\sim\mathcal{N}(\mu^{(a)},(P^{(a)})^{-1})$,按 $\hat r^{(a)}=(\tilde\theta^{(a)})^\top\mathbf{x}_t$ 贪婪行动,然后进行后验更新(posterior update)
$$P^{(a_t)}\!\leftarrow P^{(a_t)}+\tfrac{1}{\sigma^2}\mathbf{x}_t\mathbf{x}_t^\top,\qquad \mu^{(a_t)}\!\leftarrow(P^{(a_t)})^{-1}\!\Bigl[P^{(a_t)}\mu^{(a_t)}+\tfrac{1}{\sigma^2}r_t\mathbf{x}_t\Bigr].$$
精度更新 $P^{(a_t)} \leftarrow P^{(a_t)} + \sigma^{-2} \mathbf{x}_t \mathbf{x}_t^\top$
意味着:在观察到状态 $\mathbf{x}_t$ 下选择臂 $a_t$ 的结果之后,我们对该臂的奖励如何与刚刚观察到的状态维度
相关变得更加确定。均值更新则把 $\mu^{(a_t)}$ 朝着解释观察到的奖励 $r_t$ 的方向移动。在循环早期,较高的后验
方差导致频繁探索(看似随机的换臂);随着证据累积,后验收紧,老虎机便利用历史上带来更好边际改进的那个臂。这是
一个标准的贝叶斯线性老虎机——其新颖之处在于将它应用于量化研究中的因子-对-模型分配问题,而这在文献中尚无先例。
主要结果
用比经典因子库少约 70% 的因子,取得约 2 倍的年化收益,且每个循环成本 <$10。在 CSI500 上做样本外测试,系统
取得 IC 0.0288、IR 2.17;在 NASDAQ100 上,IC 降至 0.0162、IR 1.77——仍为正,但明显更弱。
局限与数据泄漏隐患
最严重的方法论隐患是经由大语言模型本身造成的潜在数据泄漏(data leakage)。测试期为
2024-2025,而所用的大语言模型(GPT-4 级别)的知识截止时间与这一窗口重叠甚至延伸其中。大语言模型可能见过
讨论这些用于样本外评估的具体股票与时期的金融评论、分析师报告,乃至学术论文。这并不意味着大语言模型记住了
具体的价格路径,但它可能吸收了某些统计规律(如"2024 年末动量在中国 A 股表现良好"),从而污染因子假设
(hypothesis)。论文承认这一风险,但没有开展受控实验——例如,在严格晚于大语言模型训练截止时间的时段上测试,
或使用一个截止时间经核实更早的大语言模型。
偏弱的 NASDAQ100 结果(IC 0.016 对 CSI300 的 0.053)值得审视。一种解读是美国大盘股
定价更有效、更难预测。但另一种解读是大语言模型的训练数据中关于中国市场的分析格外丰富(执行平台 Qlib 是
微软亚洲研究院(Microsoft Research Asia)的项目,以中国市场为重点),因此大语言模型为该市场生成了更好的
假设。在缺乏对"大语言模型知识"与"市场有效性"做消融(ablation)的情况下,成因是含糊的。
其他局限:系统完全依赖大语言模型内部的金融知识,没有领域特定的先验或市场状态(regime)适应;对于复杂的多步
任务,Co-STEER 的收敛会变慢(如 Pass@k 分析所示);因子-模型交互仍然不透明——其可解释性不及符号回归
(symbolic regression);成本约束(每次运行 $10、约 6 小时)限制了探索深度。最关键的是,尽管每次运行评估了
大量候选因子,却没有施加任何 DSR 或 PBO 修正。
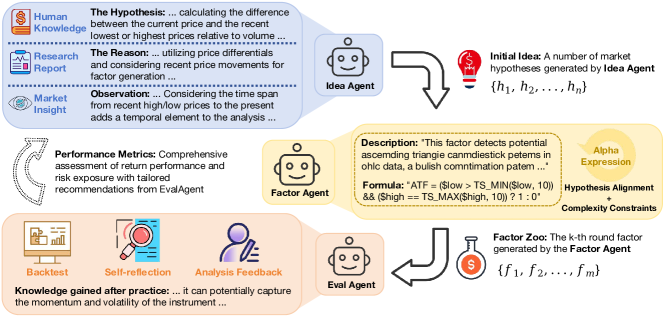
AlphaAgent — 抗衰减的大语言模型挖掘(decay-resistant LLM mining)
核心思想。这是首个正面应对阿尔法衰减(alpha decay)的大语言模型挖掘器。三个智能体
(Idea → Factor → Eval)运行一个闭环,并配有三个正则化器(regularizer):基于抽象语法树(abstract syntax
tree, AST)的原创性(originality)(新因子在结构上必须有别于已有因子)、假设-因子一致性
(hypothesis–factor alignment)(公式必须真正实现所陈述的论点),以及复杂度控制(对过度工程化
施加惩罚)。
为何阿尔法衰减重要——以及原创性强制为何针对它
阿尔法衰减(alpha decay)是这样一条经验规律:一个盈利的交易信号会随时间丧失预测力。其机制是拥挤
(crowding):一旦某因子为人所知(被发表、被逆向工程,或被独立地重新发现),资本便涌入利用它的交易,价格
随之调整,信号的期望收益被压缩趋向于零。对于一个新颖的另类数据信号,半衰期可能是数月;而对于流动性市场中
一个众所周知的异象,半衰期则几乎是瞬时的。本研讨中此前的每个系统(Topics 1-4,以及上文的 RD-Agent(Q))都
忽视了这一动态:它们挖掘因子、报告回测(backtest)表现,并隐含地假设这种优势会延续到实盘交易中。AlphaAgent
的核心论点是:如果挖掘过程本身强制结构性新颖——确保每个新生成的因子都不同于已知因子的现有知识库——那么所得
因子在部署时就不太可能已经拥挤。这是一个必要但不充分的条件:一个结构上新颖的公式仍可能捕捉到与某个已有公式
相同的经济效应,而生成时刻的新颖性也无法阻止未来的拥挤。但它仍是一个站得住脚的一阶启发式,而此前没有任何
系统尝试过。
架构
Idea agent (chain-of-thought)观察 → 知识 → 理论 → 规格 ⇒ 假设(hypothesis)$h$
↓
Factor agent + 3 regularizers原创性 $S(f)$ · 一致性 $C(h,d,f)$ · 复杂度 $R_g$
↓
Eval agent → feedback loopIC/RankIC、AR/IR、MDD → 回到 Idea agent;更新知识库
正则化器 1:基于 AST 的原创性及其弱点
原创性(originality)是新因子的抽象语法树(AST)与任一已知因子的 AST 之间的最大公共子树(largest common subtree),
$$S(f)=\max_{\phi\in Z}\;\max\bigl\{|t_i|:\,t_i\subseteq T(f),\,t_j\subseteq T(\phi),\,t_i\cong t_j\bigr\},$$
通俗地说:把候选因子 $f$ 和知识库 $Z$ 中每个已有因子 $\phi$ 解析为抽象语法树(abstract syntax tree, AST)。
找出在 $T(f)$ 与 $T(\phi)$ 中(在同构意义下)同时出现的最大子树。该公共子树的大小,在所有已知因子上取最大值,
即为 $S(f)$。较高的 $S(f)$ 意味着新因子与某个已知之物共享了一大块计算子结构——它会因缺乏原创性而被惩罚。
其根本弱点在于:结构相似并不等同于功能相似。两个公式可以拥有完全不同的 AST 却计算出几乎
相同的输出——例如 rank(ts_mean(close, 20)) 与 ts_rank(close, 20) 的语法树
互不相交,横截面取值却高度相关。反之,两个具有大公共子树的公式(如二者都含 ts_std(volume, 10)),
若该子树被嵌入不同的外层计算之中,最终输出可能并不相关。AST 相似度只是一个结构代理:它能捕捉复制粘贴式的
抄袭,却会漏掉语义等价。更稳健的做法是把结构检查与行为检查结合起来(如因子输出之间的两两 IC),但 AlphaAgent
并未这样做。
正则化器 2:假设-因子一致性
一致性得分组合了两个由大语言模型(LLM)评估的分量:
$$C(h,d,f)=\alpha\,c_1(h,d)+(1-\alpha)\,c_2(d,f)$$
这里 $h$ 是 Idea 智能体生成的市场假设(hypothesis),$d$ 是对该因子应当计算什么的自然语言描述,$f$ 是实际的
公式代码。$c_1(h, d)$ 一项问的是:"描述 $d$ 是否忠实地翻译了假设 $h$?"$c_2(d, f)$ 一项问的是:"代码 $f$
是否真正实现了 $d$ 所描述的内容?"二者均由大语言模型在 [0,1] 区间上打分,并以 $\alpha = 0.5$ 等权加总。
其目的是防止"假设漂移"——一种常见的失败模式:大语言模型起初有一个自洽的经济想法(如"内部人卖出减少、机构
持股上升的股票往往跑赢"),却实现了一个只捕捉其中一面或引入了无关变换的公式。通过显式地为链条
$h \to d \to f$ 打分,系统强制使生成的因子可追溯到所陈述的假设,从而提升可解释性,并降低因子回测(backtest)
表现是一桩与所提机制无关的统计偶然的可能性。其局限在于:大语言模型给出的得分 $c_1$ 与 $c_2$ 既非确定性也未
经校准:同一对(假设,因子)在重复评估中可能得到不同的分数,而大语言模型给出的 0.7 分并不带有任何频率学派的
保证。
正则化器 3:复杂度控制
复杂度惩罚聚合了符号长度、参数数目以及整合后的正则化项:
$$R_g(f, h) = \alpha_1 \cdot \text{SL}(f) + \alpha_2 \cdot \text{PC}(f) + \alpha_3 \cdot \text{ER}(f, h)$$
其中 $\text{SL}(f)$ 计数表达式树中的节点数(更长的公式受到惩罚),$\text{PC}(f)$ 计数可调参数(如窗口长度、
阈值),$\text{ER}$ 则整合了原创性与一致性:
$\text{ER}(f, h) = \beta_1 S(f) + \beta_2 C(h,d,f) + \beta_3 \log(1 + |F_f|)$。
用文字说:复杂度惩罚阻止大语言模型生成那些样本内拟合噪声、却泛化糟糕的繁复、深度嵌套的公式——这与把最小描述
长度(minimum description length)或奥卡姆剃刀应用于 alpha 公式是同一种直觉。
正则化目标,以及它为何在拟合与过度工程化之间权衡
三个正则化器组合为 Factor 智能体所优化的单一目标:
$$f^*=\arg\max_{f\in\mathcal{F}}\;L\bigl(f(\mathbf{X}),\mathbf{y}\bigr)-\lambda\,R_g(f,h).$$
第一项 $L(f(\mathbf{X}), \mathbf{y})$ 是预测拟合度——因子与前瞻收益的相关程度。第二项 $\lambda R_g(f, h)$
是正则化(regularization)的总成本,综合了新颖性、一致性与复杂度。权衡是直接的:一个取得高 IC 的因子,若是
通过抄袭某个已知因子($S$ 高)、偏离其假设($C$ 低),或使用了不必要复杂的公式($\text{SL}$ 与 $\text{PC}$
高)来实现的,就会受到惩罚。标量 $\lambda$ 控制系统在多大程度上偏好简单、原创、与假设一致的因子,而非纯粹的
预测力。这映照了机器学习中的偏差-方差权衡:增大 $\lambda$ 会降低过拟合与拥挤(crowding)风险,代价是可能拒绝
真正富含信息但复杂的因子。权重 $\alpha_1, \alpha_2, \alpha_3, \beta_1, \beta_2, \beta_3, \lambda$ 全部
依靠手工调参——论文并未学习它们,鉴于最优权衡很可能因市场与市场状态(regime)而异,这是一个重大局限。
主要结果
解读极低的美国 IC
标普 500(S&P 500)的 IC 为 0.0056,值得仔细解读。IC 为 0.0056 意味着在给定的某一天,因子得分与下一期
收益之间的横截面皮尔逊相关为 0.56%——几乎不高于零。然而系统仍取得 8.74% 的年化收益、IR 1.055,这看似自相
矛盾,直到人们意识到:即便是极小的横截面相关,只要在数百只标的与众多交易日上一以贯之地施加,再配以严格的
头寸规模管理,也能复合成经济意义上可观的组合收益。ICIR(0.0552)同样很低,意味着 IC 相对其均值剧烈波动——
许多天因子是错的,但平均而言它略微是对的。
更实质地说,CSI500 的 IC(0.0212)与标普 500 的 IC(0.0056)之间的反差——近 4 倍的差距——有力地证明了
有效市场抵抗自动化 alpha 挖掘。标普 500 是全世界被分析得最透彻、流动性最强、被套利得最充分
的股票池;任何大语言模型(LLM)能从公开知识中表述出来的异象,很可能早已被发现、交易并套利殆尽。CSI500
尽管日益有效,仍包含分析师覆盖较少、散户参与更多、并带有结构性摩擦(T+1 结算、卖空约束)的中国中盘股,这些
因素使异象得以持续更久。这种市场有效性梯度是本研讨全部六个系统中最重要的单一经验规律:每一个都在中国股票上
表现优于美国股票。这并非任何单个系统的弱点——它是关于公式化 alpha 在发达市场之极限的一个论断。
消融实验要点
原创性正则化器是影响最大的单一组件:有了它,命中率(生成因子中通过回测阈值的比例)提升了 81%,假阳性率
从 0.29 降至 0.16。整体成功率从 0.75 升至 0.83,而 token 效率——每花费一个大语言模型 token 所得的有用因子
数——提高了 23%。这印证了如下直觉:迫使大语言模型远离"显而易见"的因子(这些因子往往已被知晓且已拥挤),会
产出更高比例的可行候选。
通向 Topic 7 的线索。RD-Agent(Q) 与 AlphaAgent 都已闭合自主循环——因此"大语言模型
(LLM)提出 alpha"本身已不再新颖。二者都没有做到的是:把预测目标从横截面 IC 改为一个条件事件概率,
在任务选择上进行搜索,或把通缩(deflation)接入循环。两个系统问的都是"哪些股票会跑赢?"——没有一个
去问"鉴于这只股票刚刚发生了这一具体事件,$P(\text{favorable outcome} \mid \text{features})$ 是多少?",
也没有一个施加 DSR、PBO 或 HLZ 修正,以计入搜索过程中评估过的成千上万个假设(hypothesis)。这正是该方案所
占据的空白。
局限。美国 IC 极低(0.0056)——有效市场抵抗;正则化器权重靠手工调参;大语言模型的一致性
得分非确定且未经校准;AST 相似度只是一个会漏掉功能等价的结构代理;阿尔法衰减(alpha decay)虽借由新颖性
强制得到缓解,却从未被显式地建模为一个动态过程——没有衰减率估计、没有市场状态(regime)检测、没有半衰期
测量;没有 DSR/PBO。